Turning a Document Swamp into an Organised Knowledge System with AI
Enterprise documentation rarely stays organised for long. As companies grow, knowledge fragments across systems, folders, and inboxes — creating retrieval bottlenecks that cost teams hours each week. Artificial intelligence offers a practical path out. This article explores how retrieval-augmented generation (RAG) and semantic search can transform chaotic document swamps into structured, queryable knowledge systems, covering the underlying technology — vector databases, embeddings, and chunking — alongside real-world implementation patterns.

If only finding the right information at the right time were as easy as firing up a quick Google search. Multiple surveys and studies paint a different picture for knowledge workers across industries, one where they spend hours a week hunting down the necessary piece of information:
- APQC estimates that an average knowledge worker loses 8.2 hours a week searching for information.
- Adobe's 2023 survey reveals that 48% of workers struggle to quickly find a specific document.
- Atlassian's 2025 State of Teams report puts the figure at 25% of the workweek. According to it, over half of workers also often have to ask someone or schedule a meeting just to get the information they need.
- Slite's survey shows that internal enterprise searches have a mere 10% first-attempt success rate.
While digital disorganisation is a source of frustration for employees, that's not the only reason to care about it. One in two knowledge workers says teams unknowingly waste time working on the same thing. Facilitating search is also the number one roadblock to productivity, with 43% of knowledge workers saying quicker retrieval would allow them to work faster.
That's not to mention version-control nightmares, compliance risks, stalled cross-team collaboration, slower onboarding, and potential security breaches stemming from documentation chaos.
How come companies let documentation get out of hand? That depends:
- Startups and fast-growing companies rarely treat a centralised document management strategy as a priority. Without one, files reside in silos, naming conventions are nonexistent, and some knowledge doesn't get documented at all. Time passes by, allowing the document swamp to form.
- Large organisations, in turn, find themselves facing an overwhelming number of legacy systems, silos, and standalone file-sharing platforms. Traditional records management methodologies that worked well for paper records no longer work for the volume and velocity of digital information. Untangling the document management chaos becomes an undertaking worthy of being one of Hercules' Twelve Labours.
Traditional approaches, which rely on manual approvals or filing, only complicate document retrieval and increase document processing cycle time. Overlooking data integration and interoperability challenges while using an average of 897 apps, in turn, reinforces silos. Lack of version control leads to confusion and mistakes, while important documents are accidentally deleted or misplaced.
The traditional approach isn't working. So, it's high time to adopt a new approach to document management — one powered by artificial intelligence (AI).
Understanding the AI Solution: RAG and Semantic Search
Artificial intelligence is a vast domain that encompasses diverse technologies, from computer vision to natural language processing. A new approach to document management relies on two of them: retrieval-augmented generation and semantic search.
What Is Retrieval-Augmented Generation (RAG)?
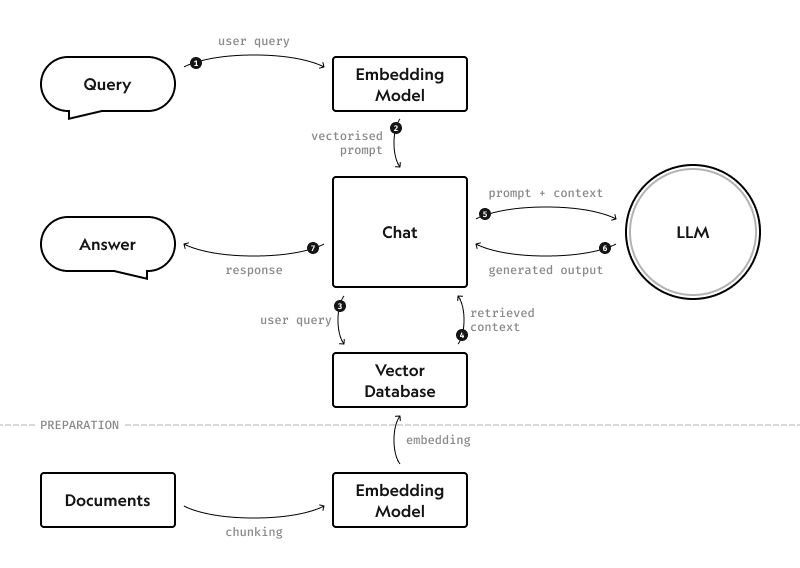
Retrieval-augmented generation (RAG) is a technique that combines large language models (LLMs) with existing retrieval systems. Initially proposed in a 2020 paper by Patrick Lewis et al., it enables LLMs to create responses based on information from specific, relevant sources.
LLMs are great at responding to prompts based on broad knowledge, but they lack in accuracy and depth when it comes to specific, source-grounded queries. That happens because LLMs can refer only to the knowledge included in the original training datasets. So, updating the knowledge requires additional training, which takes time and effort.
RAG was created to resolve this issue. With RAG, the LLM is directed to consult specific authoritative sources in real time. That's how RAG enables LLMs to create responses using the most recent information from an internal knowledge database.
Here's how RAG works in practice, in broad strokes:
- The user enters a prompt. For example: "How do I calculate the premium for our home insurance policy?"
- RAG locates relevant information in pre-defined knowledge sources (home insurance policies) stored in a vector database.
- The LLM receives relevant information from RAG and generates a response.
- The user gets a specific, up-to-date answer with the formula for premium calculation and a link to sources.
What Is Semantic Search & How Is It Different?
Semantic search is an improvement upon good-old keyword-based search. Instead of strictly looking for exact matches with the entered words, semantic search takes into account the context and intent behind the query to identify the most relevant information. In RAG systems, semantic search enables the system to consider the query context when searching for relevant information.
Think about the on-page search in any browser. Press Ctrl+F, enter a word, and the browser highlights the exact matches on the page. It won't even highlight different word forms: if you type in "bubbles," any instance of "bubble" or "bubbling" will be missed.
Semantic search won't just consider different forms of the entered words. It will also consider other possible ways to phrase the query. For example, if you type in "Q2 roadmap," semantic search will consider synonyms such as "Q2 planning doc" or "latest product roadmap."
Semantic search is powered by several AI technologies:
- Natural language processing (NLP) to interpret human language and identify context and intent
- K-Nearest Neighbours machine learning algorithm to identify commonalities and close matches
- Transformers (BERT, GPT) to understand relationships between words and phrases
- Contextual analysis to adapt results to every user's behaviour and query context (location, time, device, etc.)
The Role of Embeddings and Vector Databases
It might be easy for humans to understand that "his majesty" and "king" mean the same thing, but that's not the case for computers. Since they operate using numbers, text and its meaning have to be translated from natural language into machine-readable data.
This is where embeddings come in. An embedding model plays the role of a human-machine translator. Trained on billions of sentences, it converts the text input into a list of numbers (vector).
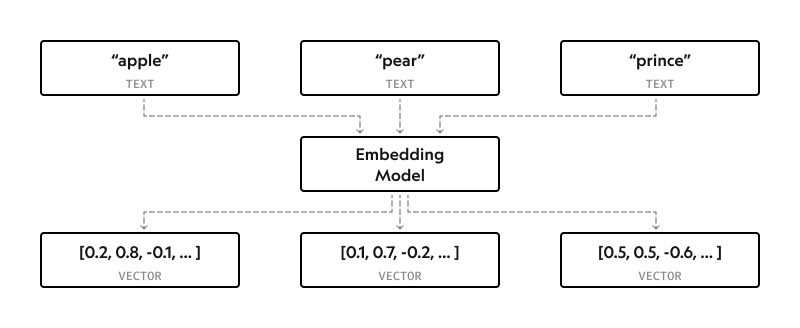
The values in the vector allow the model to determine semantic similarity between words based on geometric proximity.
N.B. Images and audio can also be turned into embeddings.
Before embedding can take place, documents need to be broken down into chunks on the sentence or paragraph level. Then, each chunk is turned into an embedding. Chunking helps save on API costs since you feed only a small part of the document into a third-party AI model.
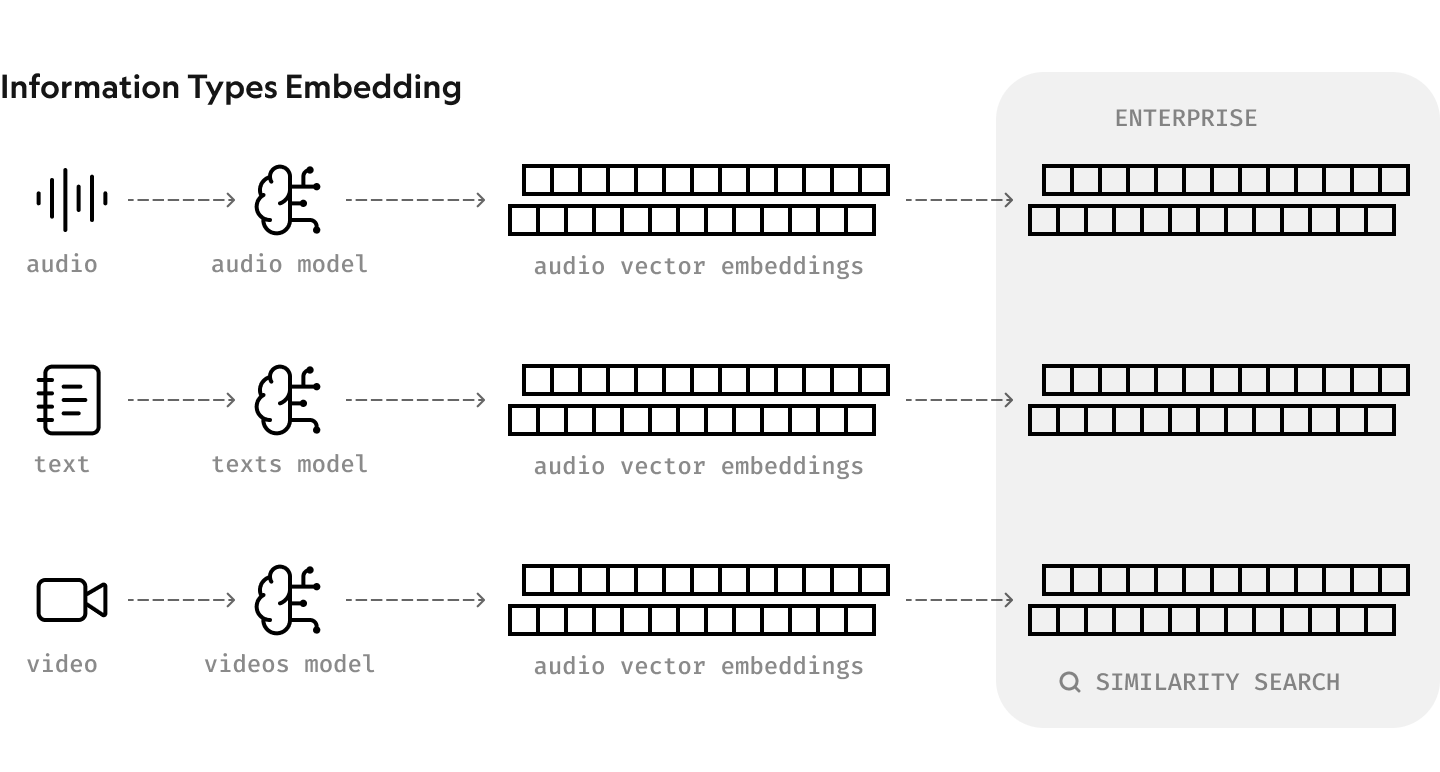
Once the data is converted into vector embeddings, it can be stored in a database. There is a special type of database designed for managing and retrieving this type of data: a vector database. It can handle the entries that are simply too complex for traditional scalar-based databases.
Popular vector databases include:
- Chroma
- Pinecone
- Weaviate
- FAISS
- Qdrant
Vector databases have multiple advantages over traditional ones, such as:
- Advanced indexing and search methods
- CRUD operations support
- Metadata filtering
- Horizontal scaling
The result? Similarity searches are faster and more efficient, supporting high performance for the RAG solution.
Vector databases can also store data in multi-layered graphs. Think of it as a map that helps the search algorithm pinpoint where it should look for relevant entries. So, instead of searching the entire database for matches, the algorithm only needs to look through its specific part.
Ultimately, the vector database determines how fast your search will be. The better you organise the data in layers, the easier it'll be for the algorithm to identify matches quickly. The embedding model, in turn, will impact the quality of your search.
Why This Matters for Documentation
RAG, semantic search, embeddings, and vector databases come together to power intelligent document search. Unlike traditional approaches, it:
- Provides instant answers to queries in natural language
- Takes context into account to locate relevant information
- Doesn't require an exact match to locate relevant information
In comparison with using LLMs on their own, RAG also:
- Reduces hallucinations, thus improving response accuracy and reliability
- Provides tailored, specific responses based on pre-defined sources without training a model on them first
- Helps maintain data privacy (training a third-party model on proprietary data puts that data at risk of exposure)
- Reduces upkeep costs since using the most up-to-date information doesn't require retraining the model
From Chaos to Clarity: Key AI Capabilities
Depending on their complexity, RAG systems can be built using one of three architectural approaches:
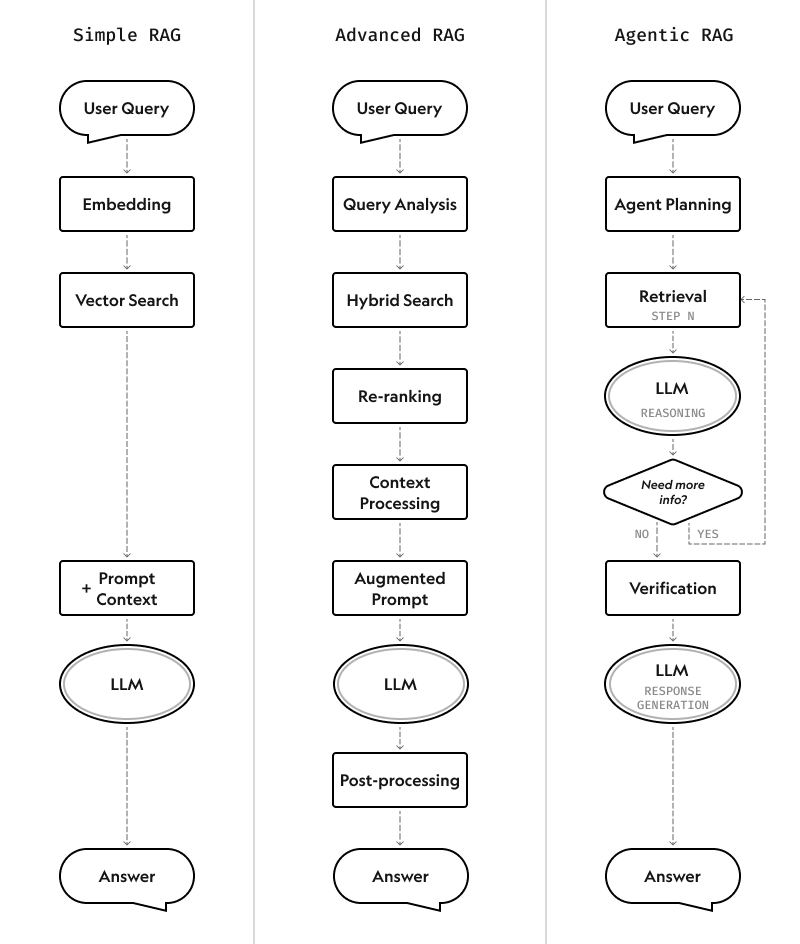
Today, there's no need to build a RAG solution entirely from scratch, adding to its cost-effectiveness for organisations. LangChain and LlamaIndex are two common frameworks used to build RAG search systems:
- LangChain is an open-source NLP application development framework. It offers a wide range of tools to speed up their creation, including a pre-built agent architecture and integrations with 1,000+ tools and models.
- LlamaIndex is a data indexing and querying framework that supports 94 file types (PDFs, spreadsheets, images, audio, presentations, text documents, etc.). It's designed for search and retrieval tasks and can handle large datasets without performance dips.
| LangChain | LlamaIndex | |
|---|---|---|
| Key focus | NLP application development | Search and retrieval |
| Key features | Prompt creation and management Integrations with third-party AI models Memory management Chain building and management Pre-built, customisable agents | Data conversion into a searchable vector index Data storage at a specified location Vector stores Embeddings using text-embedding-ada-002 or other methods Querying and retrieval Post-processing and response synthesis |
| Best for | Chatbots, including for automated customer support Complex workflows around information retrieval Advanced context retention capabilities | Quick retrieval for large volumes of diverse data Complex memory structure support LLM-powered knowledge bases without advanced content generation capabilities |
Whether you build your intelligent knowledge system with LangChain or LlamaIndex, it should include these four key capabilities to ensure output accuracy, relevance, and reliability.
Automatic Content Discovery Across Multiple Sources
First things first: the AI-powered knowledge system has to ingest data from somewhere. To that end, developers build connectors to integrate the system with specific data sources (file storage, third-party tools, etc.).
Bringing all of your data sources into a single index will help you combat silos. A user will no longer need to type in the same query in multiple separate tabs or windows. They just need to enter it once into the AI system, and it'll search data across multiple sources, from CRMs and ERPs to the intranet and your website.
However, just adding the connectors isn't enough if the system must always have real-time information at hand. In that case, it'll need a real-time data pipeline that consists of:
- Data collector with connectors to integrate data sources into the pipeline
- Change detection system that identifies whether content has changed to avoid unnecessary processing
- Vector update engine with batch processing and incremental embedding generation for efficiency
- Dynamic retrieval that adapts to query types and data freshness requirements
Real-time updates are important for systems that:
- Support financial trading decisions
- Reply to ticket-related customer support queries
- Enable e-commerce recommendations based on the current inventory levels
- Power news aggregation platforms
Context-Aware Information Retrieval
By default, RAG systems remove context when encoding information. This severely reduces their ability to return relevant responses. This is where contextual retrieval comes in: it preserves context, reducing failed retrievals by 49% and improving accuracy.
Contextual retrieval comprises two submethods:
- Contextual embeddings. The system adds chunk-specific explanatory context to each entry before embedding.
- Contextual BM25. The system creates a BM25 index. BM25, or Best Matching 25, is an older ranking technique that identifies precise word or phrase matches with lexical matching.
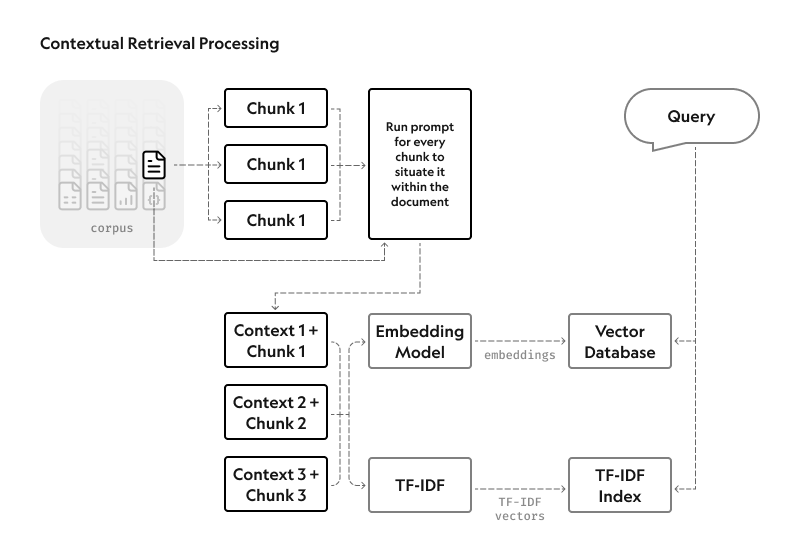
Hybrid retrieval techniques that combine keyword search and semantic search come in handy when:
- Users need to see the source because they don't trust the AI-generated answers
- Users want to explore instead of posing specific questions
- Users already know which file they're looking for
Context-aware retrieval finds its uses in:
- Research assistance for market analysis, pharmaceuticals R&D, or academia
- Financial analysis based on specific documents and the analyst's preferences
- Medical information retrieval for a specific patient
Gap Identification and Duplicate Detection
Only one in six enterprises reports no impact from data quality issues like incomplete or duplicate records. Incomplete customer profiles and duplicate records remain in the top five data challenges.
Removing duplicates isn't as simple as locating the exact matches across multiple data sources. The same information may be stored in different formats or phrased somewhat differently. For example, the same customer can be referred to as "John Doe" and "John M. Doe" across two systems. Therefore, basic text-matching isn't enough.
AI can detect records or files with duplicate information despite subtle differences in phrasing, spelling, and format. Fuzzy matching, or approximate string matching, measures how similar two values are, with higher scores indicating a stronger match. Similarity itself can be calculated using different approaches:
- Character similarity: The number of edits or swaps and their location; good for detecting typos
- Token overlap: The number of shared tokens between two values; good for matching addresses and long names
- Phonetic similarity: The match in phonetic transcription; good for catching transcription errors, misspellings, and words spelled differently across dialects
- Semantic similarity: The match in the meaning of the text; good for long-form text (product descriptions, etc.)
Removing duplicates reduces storage and processing costs and prevents errors in financial or administrative workflows.
As for incomplete records, AI systems can detect missing values based on patterns in historical records. For example, they can define the expected data elements for each document type, such as diagnosis codes for patient records. That's called gap identification.
If the missing data is publicly available or in other internal records, the AI system can fetch it and fill the gap through data enrichment. For example, if the client's address is missing from the B2B CRM system, the AI system can add it from the company's website.
Cross-Referencing and Relationship Mapping
Cross-references are links that connect a specific part of the document or record to related information stored in another file or location. For example, a product roadmap may include a reference to a file that describes buyer personas.
Cross-referencing is the necessary first step before standardising its formats (e.g., naming conventions, identifiers) and reconciling records to resolve inconsistencies across systems. This improves data quality and, therefore, reliability.
LLMs can go beyond fuzzy matching to pinpoint related data based on semantic similarity and context, thus helping teams connect and reconcile records faster. One AI tool, for example, can automate an estimated 70% of the entity and record linkage process.
More importantly, cross-referencing in AI systems can be used to retrieve the same information from multiple sources to verify its accuracy. For example, when asked to provide the customer's name based on an ID, the AI system can check it in the CRM, billing system, and helpdesk software.
Similarly, AI-powered relationship mapping is faster, more comprehensive, and more accurate thanks to context awareness and natural language processing. Relationships describe dependencies and interactions between different entities, people, objects, and so on.
Traditionally, relationships are mapped manually. For example, an employee would spend their time creating a stakeholder chart in Canva, relying on their memory and enterprise data. When the chart needs updating, someone would have to update it manually. It's time-consuming, prone to human error, and hard to scale.
An AI system can automate relationship mapping using real-time data from multiple sources: CRMs, ERPs, etc. Those relationships can be sorted into categories, such as lineage, transactional, dependency, ownership, and temporal. What's more, generative AI models can quickly visualise these relationships for decision-makers in charts and diagrams.
Relationship mapping is especially useful for:
- Revealing fraud schemes involving multiple parties or rings
- Gaining visibility into multi-tier supply chains and potential points of failure
- Identifying cross-selling paths for customers
Practical Applications and Use Cases
RAG and semantic search can be powerful additions to enterprise knowledge management, documentation processes, and LLM chatbots. Let's take a look at these use cases in more detail, along with real-world examples of companies that have already introduced them.
Consolidating Scattered Knowledge Bases
Every team may have its own approach to knowledge storage and sharing. The result? Information is fragmented across documents, internal tools, platforms, messengers, and emails.
A Slite survey found that 64% of employees use between 1 and 3 tools to search for information every day, and 31% have to navigate 4 to 6 tools. For respondents, the solution is evident: a centralised interface is the number one search improvement they want to see.
An LLM-powered chatbot, combined with RAG, can become that centralised interface for knowledge workers. It can tap into the whole wealth of information, whether it's stored in a corporate wiki, note-taking tool, project management software, or an internal policy document.
This doesn't just enable workers to be more productive. Onboarding new hires becomes faster, too: they can get their questions answered without waiting for a senior employee to have free time.
Limitations to Keep in Mind
The chatbot's responses will only be as good as the information in the connected data sources. In other words, poor-quality data will lead to poor-quality responses. To avoid this "garbage in, garbage out" scenario, review your internal documents and ensure only up-to-date information gets added to the vector database. Maintain knowledge currency over time, too.
Case in Point: RBC's Investment Policy RAG System
The Royal Bank of Canada (RBC) has developed a wealth of proprietary methods and guidelines for financial advisors. But that wealth of data, stored in disparate documents across its internal platform, wasn't easily accessible. So, highly specialised questions ended up in a lengthy backlog, resulting in a bottleneck in delivery and response times.
To help financial advisors get answers faster, the RBC deployed Arcane, a RAG-enhanced chatbot that retrieves information from internal documents and policies and feeds it into an LLM. The model then generates an answer in natural language, along with links to sources.
Thanks to Arcane, employees no longer need to perform multiple searches across web platforms, PDF documents, Excel tables, or other proprietary sources of information.
Working with semi-structured data represented the biggest challenge for the team building Arcane. The structured sets of data often used inconsistent methods and standards. Other sources were unstructured altogether. Working with this variety of data required the company to tailor its parsing approach and make it versatile enough to handle the diversity of data across the sources.
Generating Unified Documentation from Diverse Sources
Manual data entry costs businesses an average of $28,500 per employee annually, according to a Parseur study. That involves taking data from PDFs, emails, and other sources and adding it to digital systems. Manual reporting is another productivity drain, and it's even more noticeable in roles where reporting is common (data analysts, project managers, etc.).
Thanks to RAG and natural language generation, AI systems can cut down the time spent on manual reporting by up to 80%, according to Forrester.
RAG ensures the system uses the most up-to-date information possible, while the LLM summarises it and presents it in the desired format. The model can also be trained on past reports to match the format without explicit instructions. And the best part? The LLM can work with unstructured data like emails and text files.
Limitations to Keep in Mind
It's best to consider the generated reports as first drafts. The user still needs to review its contents and verify that all data is correct, lest they end up in hot water like one lawyer who submitted a motion filled with hallucinated citations. The format may also need to be adapted depending on the user's context.
Case in Point: Grab's Analytical Reports
Data analysts at Grab, a super-app popular in Southeast Asia, routinely found themselves swamped with diverse data requests from stakeholders. To fulfil them, they had to repeat the same SQL queries over and over again, with only slight modifications to their parameters.
So, the Integrity Analytics team turned to RAG and LLM to automate routine tasks like creating metric or fraud reports. The team chose RAG over fine-tuning the LLM due to three factors:
- Lower costs and less effort required
- Access to the latest information by default
- Higher speed and scalability
The team's new tool uses SpellVault, a RAG tool that calls relevant knowledge vaults and plugins to answer the user's question submitted via Slack. Data-Arks, an in-house Python API platform, executes the necessary SQL queries and sends its output to the LLM. The model then summarises the data and presents key insights in an easy-to-grasp format.
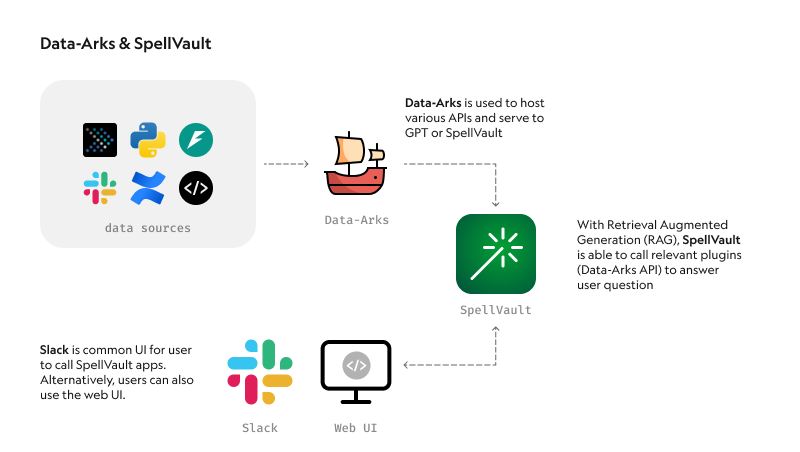
The company estimates that this feature alone saves the team an estimated three to four hours per report generated.
On top of report generation, Grab also has a dedicated LLM fraud investigation helper called A\* bot. It works in a similar way: the prompt sent via Slack triggers automatic SQL queries, with the output summarised by the LLM.
Creating Intelligent Documentation Assistants
What if you could get the key takeaways from any given document at the press of a button? Or turn notes into a structured report? That's another way RAG and LLM can save knowledge workers time. For example:
- A compliance officer could get a quick summary of the upcoming regulatory changes applicable to the company
- A legal analyst could speed up their research with concise references to past cases and relevant clauses
- A business analyst could review the main points brought up during the previous meeting before heading into the next one
These intelligent document assistants do more than answer questions. They summarise documents, generate first drafts, translate foreign-language sources, and help edit drafts for clarity and conciseness.
Limitations to Keep in Mind
If you simply use RAG and semantic search, your solution won't be able to scan, compare, and reason across all documents at once. It'll only be able to locate the most relevant file or record and return it. To overcome this limitation, combine RAG with metadata, SQL querying, and LLM agents.
Case in Point: C.H. Robinson's LangChain Assistant
C.H. Robinson, one of the largest logistics providers worldwide, has one mission: to provide instant service. But the clients' preference for placing orders the old-fashioned way (by email) clashed with that mission. The reason? Manual data entry was slowing down the ordering process.
The company used LangChain to build an AI assistant that would use the information from a given email to create price quotes, place orders, and schedule pickup appointments. If some data is missing, the assistant will detect it and fetch it from internal databases when possible.
Thanks to this automation, the company saves more than 600+ hours on this task alone.
Streamlining Support with Intelligent Chatbots
Until fairly recently, customer support chatbots could only guide the user through pre-defined resolution paths. Those chatbots were rule-based. Modern LLM-powered chatbots can handle more complex queries and return more personalised responses, all while retaining the conversation's context.
But to do so effectively, they have to take into account the company's policies, processes, and knowledge bases. RAG allows for deploying chatbots without having to train the LLM on the company-specific data first. Plus, all responses will rely on the latest information available in the database.
Limitations to Keep in Mind
Hallucinations or incorrect answers can lead to liability. For example, in 2024, Air Canada was ordered by a court to pay the customer who was promised a discount that didn't exist. A separate layer for verifying response quality, accuracy, and compliance is one way to prevent such scenarios.
While chatbots are efficient at handling routine queries, complex issues still require human agent intervention. Ensuring its effectiveness in the long run also requires continuous data collection and analysis.
Case in Point: DoorDash's Delivery Support Chatbot
DoorDash works with thousands of independent contractors ("Dashers") who perform deliveries on its behalf. Sometimes, they encounter issues in the process and need DoorDash's help to resolve them.
To speed up and scale Dasher support, the company decided to implement a chatbot powered by an LLM and RAG. Thanks to it, Dashers can get answers to their questions instantly, rather than browsing multiple knowledge base articles, all in their preferred language. It has also proven itself to be more flexible than the existing automated support system that relied heavily on pre-built resolution paths.
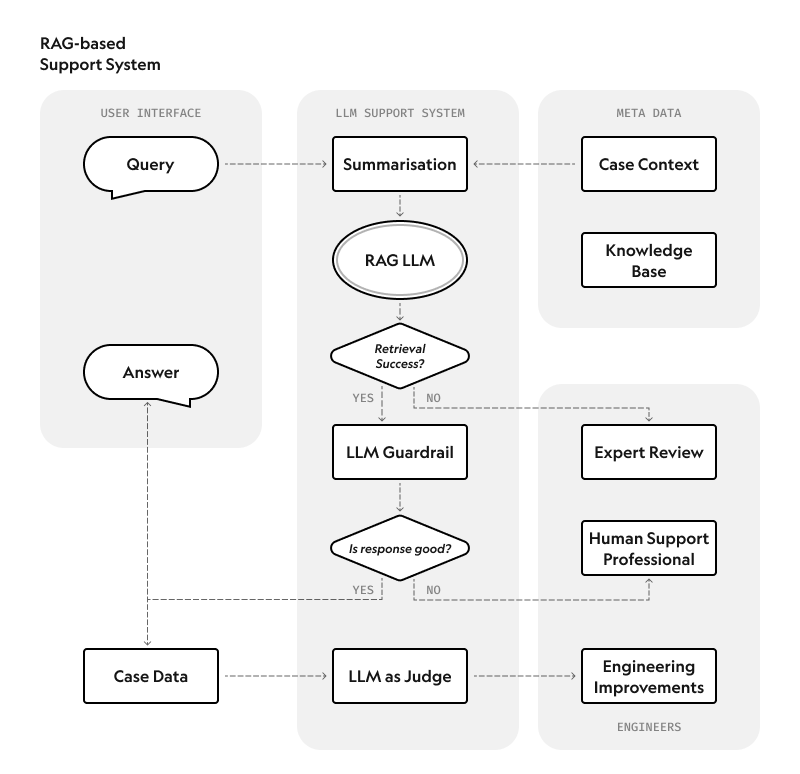
DoorDash's system consists of three components:
- RAG system that uses knowledge base articles to inform the generated responses
- LLM Guardrail system that assesses each output from the LLM to prevent hallucinations and ensure accuracy
- LLM Judge that monitors response quality based on data from thousands of manual chat transcript reviews
4 Implementation Considerations to Keep in Mind
While RAG-augmented document search and knowledge sharing have their benefits, they're not perfect. Its implementation comes with several significant risks:
- Inaccurate responses. Even though RAG reduces the risk of hallucinations, it doesn't eliminate that risk completely. That's why benchmarking the model and continuously monitoring its performance are a must.
- Compliance and security risks. Third-party LLM vendors may log all activity, even if the prompt and/or response contain sensitive data. That increases the risk of exposure and carries privacy compliance risks. Furthermore, RAG solutions are still vulnerable to attacks like prompt poisoning.
- Garbage in, garbage out. The solution's answers are as reliable as the information contained in the vector database. That's why it must be verified for quality, relevancy, and accuracy before AI processing. Standardisation can also be useful.
- Long-term scalability, performance, and ROI. As with any tech, there's always a risk of outgrowing the toolkit or selecting a less-than-suitable platform for your needs. The tech stack will also impact the upfront and running costs.
Let's break down the four key implementation considerations that address each of these risks.
Preparing Your Documentation for AI Processing
What if your sales manager asks the RAG chatbot to provide the pricing for a specific service, and it responds with outdated pricing information? That's what can happen if you plug all of your files and data into the solution indiscriminately, without preparing it first.
That's not the only possible result of poor document preparation or lack thereof. Missing data or poorly structured files may lead to incorrect or incomplete responses. Duplicates, in turn, take up space in a vector database, which may negatively impact processing and response speed.
To prepare your documents for AI processing:
- Take stock of your documentation. Conduct an inventory to identify the file types and formats and evaluate each document's relevance, completeness, and quality.
- Clean up and standardise. Remove redundant, duplicate, and outdated information from the source data. If some documents contain errors, fix them. Standardise formatting (e.g., data formats) and naming conventions. Use the same terminology throughout documentation.
- Fill the gaps. If certain information is missing, hunt it down and add it to existing documents or create new documents to host it.
- Structure the unstructured. While LLMs can work with unstructured data, they still perform better if documents are well-structured. So, ensure documents have clear subheadings, use consistent formatting, and organise information in a logical sequence.
- Add the data about data. This type of data, called metadata, enhances search accuracy by providing additional context and describing relationships. Add metadata for the document type, department, date created and updated, author, etc.
- Map relationships. They will help the AI system understand connections between documents. Add cross-references in related documents to explicitly link them. Consider adding a glossary of terms and developing a taxonomy of topics.
- Document the undocumented. Implicit or tribal knowledge has to be written down before it can be searched. Ask frontline workers and other stakeholders to put it into writing.
Choosing the Right Tools and Platforms
The toolkit used can impact everything from output accuracy to response speed and the range of capabilities the AI system possesses. That's not to mention the development and operational costs.
However, the toolkit for a RAG system isn't as simple as the LLM, embedding model, and vector database. Yes, technically speaking, these are the three tools needed for implementing the bare-bones RAG functionality. Real-world projects, however, also need monitoring, security, and evaluation. Each of these aspects requires its own tool.
Here's an overview of the tools required to build a production-ready RAG knowledge system:
| Type | Purpose/Function | Popular tools | Things to consider |
|---|---|---|---|
| Document loaders and chunkers | Parsing documents and separating them into chunks | LangChain, Unstructured.io | Source type (websites, PDFs, Notion, etc.), data noisiness, domain |
| Embedding models | Converting files and datasets into vectors | text-embedding-ada-002 (OpenAI), Cohere Embed, Hugging Face, SBERT | Retrieval quality in the applicable domain (finance, medicine, etc.) |
| Vector database | Data storage after embedding | FAISS, Pinecone, Weaviate, Chroma | Latency tolerance, pricing, deployment model (cloud/on-prem) |
| Retrievers and search | Detecting and fetching relevant chunks of content | LangChain, BM25, ElasticSearch | Suitable search type (semantic/keyword-based/hybrid) |
| LLM | Processing prompts and generating responses in natural language | GPT (OpenAI), Claude (Anthropic), Gemini (Google), Llama (Meta) | Input formats (text, images, audio), pricing, context window and output sizes, use cases |
| Prompt orchestration | Structuring and testing prompts at scale | LangChain, PromptLayer, Guidance (Microsoft) | Template needs, version control, observability and usage metrics |
| Testing and evaluation | Providing visibility into the system's accuracy, reliability, and performance | DeepEval, Flowjudge, Ragas, Uptrain | Range of metrics supported, ease of use, issue detection accuracy, alignment with use cases |
| Hosting and deployment frameworks | Hosting the RAG application | FastAPI, Streamlit, AWS Lambda + API gateway | Application architecture, performance and latency requirements, automation capabilities, scalability, security and compliance requirements |
| Caching and rate-limiting infrastructure | Optimising costs for LLM queries, embeddings, and vector searches | Redis, LLMCache, rate-limiting middleware | Compatibility with the corresponding tool |
| UI frameworks | Enabling users to interact with the application with ease | Gradio, Streamlit, React + LangChainJS | Customisability, user flow complexity, scalability, performance, responsiveness |
| Access control and security | Protecting the system from unauthorised access and data breaches | Okta's Fine Grained Authorization for ReBAC, LLMGuard, Guardrails AI | Compliance requirements, data sensitivity |
Handling Sensitive or Proprietary Information
Most likely, your RAG system will have to process at least one of the two. If this information isn't properly secured, it may end up exposed to cyberattacks and data leaks. Failing to protect sensitive data, in particular, can lead to penalties due to violations of privacy laws.
Sensitive data can include personally identifiable information (PII), protected health information (PHI), and confidential business data. To keep it safe, conduct a thorough risk assessment before implementing a RAG system. Consider potential vulnerabilities that could lead to breaches, types of cyberattacks inherent to LLMs (e.g., prompt injections), and access controls.
Following the risk assessment, define the appropriate security measures for your application. They typically include:
- Data anonymisation. Anonymise sensitive data before any processing takes place.
- Data validation and sanitisation. Check data before it's added to the database to counteract potential injection attacks.
- Access controls. Prevent unauthorised access to the vector database with granular permissions. Set up access controls for the output, as well. Differentiate access levels based on user roles.
- Encryption. Secure data at rest (in the vector database) and in transit. Vector databases may not offer encryption natively so that you may need a workaround. Use a FIPS-approved algorithm, such as AES256.
- Query validation. Check queries for malicious or harmful content before execution.
- Monitoring. Implement a tool to continuously scan system activity for anomalous behaviour and alert the team about potential attacks or breaches.
- Rate limiting. Set limits on database queries to mitigate certain types of DDoS attacks.
- API security. Secure the API endpoints if you use third-party LLMs.
AWS also suggests two architectural approaches for protecting sensitive data, namely:
- Redacting data at the storage level: Pinpointing the sensitive data at the pre-processing stage and masking it before adding it to the vector database
- Enforcing role-based access to data: Restricting access to sensitive data using user roles and permissions during retrieval
Maintaining Accuracy and Preventing Hallucinations
Even though RAG alleviates the hallucination problem, it's not a cure. Addressing it is a must for obvious reasons: hallucinations undermine trust in the RAG system and may lead users to make decisions based on incorrect information.
Preventing hallucinations isn't a one-and-done task. The RAG system needs a hallucination detection layer that would evaluate the LLM's responses for accuracy in real time. Multiple methods exist for this purpose, including:
- LLM-as-a-judge (self-evaluation). The LLM is explicitly asked to provide a confidence score assessment for the response.
- Hughes Hallucination Evaluation Model (HHEM). Vectara's method measures the factual consistency between the AI response and the retrieved context. A score of 0.9 means there's a 90% probability that the answer is factually consistent.
- Prometheus. This is an LLM designed and fine-tuned to assess LLMs' responses. It's trained on assessments of responses from various LLMs and context/response data.
- Patronus Lynx. It's another LLM created by Patronus AI and trained on various RAG datasets with annotations. It returns a pass/fail score for the LLM responses, along with a chain-of-thought breakdown for better reasoning.
- Trustworthy Language Model (TLM). Although it has "language model" in the name, the TLM is more similar to self-evaluation. It's a wrapper framework that asks the underlying LLM to evaluate its responses based on the context and question.
Several benchmarking studies have tested the reliability of these methods. Here are the results of one such study, according to which the TLM method turned out to be the most accurate:
Conclusion: The Future of Documentation Management
In a world where data is growing at a meteoric rate, ensuring that everyone uses the latest, most accurate data requires a proactive approach to documentation. Instead of frantically fixing errors in documentation after the fact or regularly weeding out irrelevant, duplicate, or redundant information, enterprises need to focus on getting documentation right when it's created. That involves ensuring that it's unique, up-to-date, comprehensive — and ready for AI processing.
As part of this proactive approach, RAG solutions can do more than automate knowledge management across an enterprise. These AI systems can also speed up new document creation, cut down search time for existing documentation, and identify and close knowledge gaps. The result? Employees can focus on more high-value tasks instead of manually entering data or hunting down the next vital piece of information.
Keep in mind that RAG-powered solutions continue evolving. For example, researchers are already pondering how to improve the performance of RAG using:
- Hierarchical information retrieval for a deeper understanding of the source materials and better performance in complex, multistep reasoning tasks
- Graph-based approaches (e.g., GraphRAG) for building detailed information hierarchies by extracting knowledge graphs from text
- Retrieval-augmented thoughts (RAT) for iteratively refining the chain of thought using retrieved information, thus making the output more coherent and contextual in the long run
- Retrieval-augmented fine-tuning (RAFT) for reaping the benefits of both fine-tuning and RAG, improving performance in highly specialised domains like medicine
McKinsey, in turn, expects to see more off-the-shelf solutions and libraries for RAG implementations in the near future. Its analysts also predict that agent-based RAG will take off, allowing systems to handle more nuanced prompts that require advanced reasoning. (These agents can seamlessly combine and rerank results from multiple sources.)
Finally, LLM providers have already started adapting to the demand for RAG. Notably, Perplexity AI has optimised its LLM for use in RAG applications.
RAG solutions that combine both graph-based and vector-based approaches, known as hybrid RAG, are also showing promise. They effectively take the best of both worlds, delivering more accurate and precise answers as a result.
Despite the promise of RAG, the technology also comes with certain challenges. Traditional RAG often can't perform aggregation operations or discern how different pieces of information relate to each other. These two issues have their solutions (SQL RAG and GraphSQL, namely). Rigid chunking rules at fixed intervals may also undermine response accuracy, while potential data leakages pose security risks.
That's why it's not as simple as saying, "Let's solve our documentation problems with RAG." First, are you certain RAG is the right approach to begin with? And if so, what kind of RAG is best suited for your enterprise data?
BN Digital can help you answer these questions — and more. Feel free to reach out to BN Digital's experts to discuss your documentation challenges.