Technical Support &
Maintenance Service
We keep your digital products performing at their best after launch. Through proactive monitoring, regular maintenance cycles and responsive support coverage, we catch issues before users do and apply updates methodically. Whether you're running cloud services on Microsoft Azure, managing on-premise backups, or coordinating remote helpdesk operations across time zones, our team handles it so yours doesn't have to. Through rigorous SLA management and hands-on engineering, we give your teams confidence that systems will continue to operate reliably.
Maintenance Built on
Prevention Rather Than Firefighting
[✳]Most organisations treat post-launch support as a necessary evil. Something breaks, someone scrambles to fix it, and everyone moves on until the next incident. Real maintenance is about prevention: proactive monitoring, regular updates that prevent security vulnerabilities and performance degradation, and systematic reliability improvement. Our approach starts by understanding your systems, their criticality, and your SLA requirements.
We implement monitoring for application and infrastructure health, covering server image replication, network configuration, endpoint protection, and critical systems health monitoring. We establish regular maintenance windows and respond to issues within agreed timeframes. Rather than treating each incident as a surprise, we build the systems that make incidents rare and predictable.

System uptime and reliability
Achieved through proactive monitoring, regular maintenance, rapid response, infrastructure monitoring, backup systems and remote monitoring that prevent user-facing incidents before they occur.
Security vulnerability coverage
Delivered by systematically applying security patches, monitoring vulnerabilities, GDPR compliance, SOC II compliance, ransomware prevention and phishing attack mitigation across all systems.
Reduction in user-facing incidents
Enabled by regular optimisation, monitoring for degradation, network security, workstation performance, storage capacity management and application health tracking.
Reduction in operational burden
Achieved through routine maintenance, incident response, on-call coverage, desktop support services, troubleshooting and infrastructure refresh that free your team to focus on growth.
Proven Support Solutions
We Deploy Across Industries
[✳]We deliver support solutions built on the specific challenges our clients face most often. Each solution reflects production experience across dozens of deployments in regulated industries and high-availability environments. Rather than generic monitoring, we design support architecture that fits your systems, your SLAs, and your team's capacity. The patterns below represent battle-tested approaches that we've refined through repeated deployment.
On-call coverage with SLAs, triage and escalation procedures supported by certified remote technicians and level 3 experts. We handle remote emergency IT, on-site support when needed, and customise help desk workflows to match your existing processes. Escalation paths are clear and communication templates keep everyone aligned when incidents occur.


Application performance monitoring, infrastructure health tracking, user experience analytics and server-to-storage visibility. We monitor switches, workstations, networking, telecommunications and cloud services through unified dashboards. IT discovery establishes your baseline; infrastructure deployment and monitoring ensure nothing falls through the cracks.


Systematically applying security patches and dependency updates, managing cybersecurity posture, backup and disaster recovery planning and business continuity. We deploy Microsoft Sentinel, SIEM, endpoint protection, ransomware prevention, phishing mitigation and encryption across your infrastructure. Security is not reactive—it's built into your maintenance cadence.


Database health monitoring, backup procedures, integrity checks and performance optimisation. We support cloud backups, on-premise backups and real-time product data pipelines that keep your data available and performant. Database administration becomes routine rather than reactive.


Infrastructure utilisation analysis and scaling strategy, Microsoft Azure management, cloud storage, hybrid setup design, cloud subscriptions and Microsoft 365 administration. We manage Exchange Online, SharePoint, OneDrive and Teams across your organisation. Cloud infrastructure becomes an operational asset, not a black box.


Where We Provide Support
)We provide support across industries where system reliability and data security are non-negotiable. The specific technologies vary, but the underlying pattern is the same: systems that need to work predictably, teams that need to focus elsewhere, and users who expect things to keep working.
- Asset Management & Investment
- Fintech & Payments
- Banking & Financial Services
- Healthcare
- Audit & Assurance
- Insurance
- Manufacturing & Distribution
- Professional Services
Case Studies
[3]- Trading App

How we built a demo-ready mobile trading app that unifies stocks, mutual funds and bonds in one account for a pre-seed fintech startup, with 100% feature coverage at investor demo.
- AI-Driven Compliance Monitoring Software

How we built an AI-driven compliance monitoring platform that reduced detection time from 28 days to 3 — covering 80+ sources across 37 jurisdictions and 21 languages for a leading European payment processor.
- Quicked7
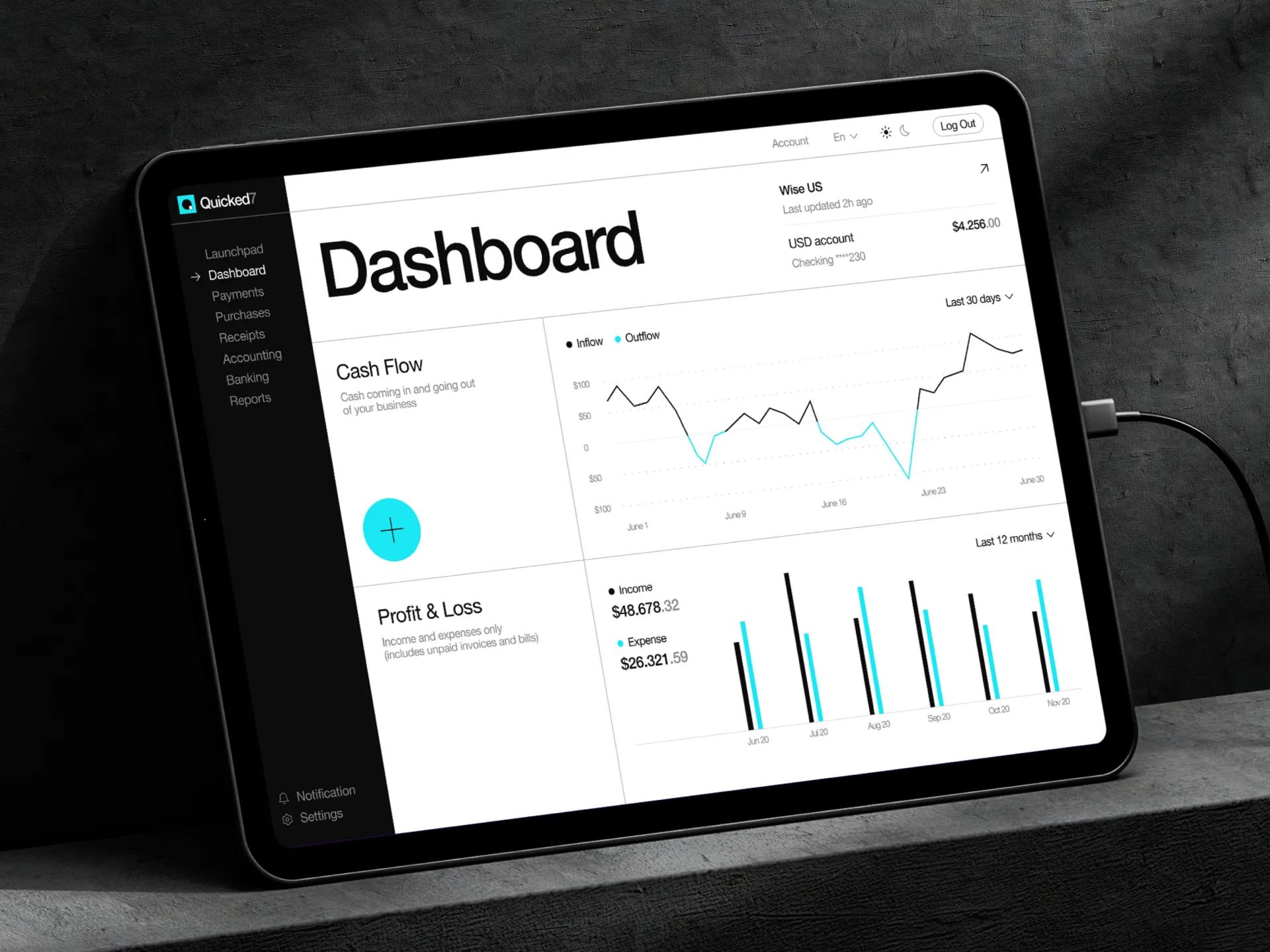
Automated bookkeeping and invoicing platform
UK SaaS platform for freelancers that automates bank reconciliation, invoice generation, and payment tracking without requiring users to understand accounting concepts.

Requirements to Reliability:
Our Support Framework
[✳]Every organisation's systems, compliance requirements and SLA expectations are different. A trading platform and a healthcare network have nothing in common except that they both need to work reliably. We begin by understanding what failure means for your business, then design support that makes incidents rare and manageable.












Engagement Models
for Support
[✳]Monthly or Quarterly Support Retainer
The primary model for ongoing support with dedicated team capacity, SLAs and on-call coverage. All-inclusive IT support plans that cover monitoring, maintenance, incident response and escalation. Works best for organisations that want predictable costs and priority scheduling without scaling internal headcount.
Business Hours Support Coverage
Support during business hours with escalation paths for critical issues that occur outside coverage windows. Cost-effective for organisations whose workloads can tolerate delayed response to non-critical incidents, or who maintain internal coverage for critical systems.
Time & Materials (Support Surge)
Additional capacity during launches, major updates or seasonal peaks when your internal team needs more hands. Billing based on actual hours worked; no long-term commitment required. Ideal for temporary capacity needs or specific projects requiring specialised expertise.
Embedded Support Team
A dedicated support team embeds within your organisation, handling day-to-day support, on-call duties and routine maintenance as direct reports to your technical leadership. This model works best for large, complex infrastructures where deep context and rapid response are essential.

FAQ
[7]How do you support remote workforce and collaboration?
We support remote workforce operations through managed Microsoft Office 365 and Google Workspace deployment, Microsoft Teams configuration, SharePoint and OneDrive management, and Exchange Online administration. We also handle Microsoft Active Directory setup, desktop support services across distributed teams, remote helpdesk and remote technical services, and video conferencing infrastructure. Microsoft migration consultants on our team can handle transitions from legacy systems to cloud collaboration platforms.
What IT project management and consulting services do you offer?
We provide IT assessment and technology assessment to establish your baseline, IT infrastructure project delivery for new implementations, and cloud migration planning and execution. Our strategic IT consulting helps organisations define technology roadmaps aligned with business goals. We also offer internal auditing, SIEM deployment and configuration, and Microsoft migration consulting for transitions from older platforms. Smart hands IT services cover hands-on deployment and configuration work.
What industry-specific IT solutions do you provide?
We have experience deploying support solutions across healthcare, legal, financial services, manufacturing and distribution industries. Each sector has specific compliance requirements—regulatory compliance, GDPR, SOC II—that we build into our monitoring and security procedures. We support application deployment across industries, manage enterprise systems, handle hardware replacements and network repair, and provide on-site IT services tailored to industry constraints. Customised IT support is always available.
What help desk and technical support channels do you offer?
We provide certified remote technicians for first-level support, advanced troubleshooting for complex issues, desktop reimaging and hardware IT support. We handle infrastructure refresh projects, staff our customisable help desks with trained personnel, and offer remote help desk services. Application support service for specific business systems is available, as is IT staff augmentation for temporary capacity needs. Queue dissolution and network repair services are part of our support toolkit.
How do you manage IT infrastructure?
IT infrastructure management starts with IT discovery—understanding what you have, how it's configured, and what it can support. Infrastructure assessment informs infrastructure deployment decisions. Ongoing infrastructure monitoring tracks health continuously. We manage backup systems, network configuration and network security comprehensively. Storage, switches and workstation management round out the picture. We help define your technology roadmap and provide on-site IT services when needed.
How do you approach cybersecurity and data protection?
Cybersecurity starts with assessment of your current posture and build of a comprehensive defence strategy. We ensure GDPR compliance and SOC II compliance through systematic procedures. Microsoft Sentinel and SIEM deployment provide real-time threat visibility. We design and implement backup and disaster recovery plans that actually work when tested. Business continuity planning ensures your organisation can survive system failures. Ransomware and phishing prevention are built into your infrastructure and user training. Encryption and endpoint protection complete the security picture.
What cloud services and infrastructure do you manage?
We manage Microsoft Azure infrastructure, supporting cloud migration from on-premise systems and hybrid cloud setups. Microsoft 365 and Office 365 administration, Exchange Online and OneDrive management, SharePoint configuration and Microsoft Teams deployment are all part of our cloud practice. Cloud backup services, cloud storage design, cloud computing cost optimisation, and cloud subscription management keep your cloud infrastructure efficient and cost-effective. Email hosting and cloud migration projects round out our cloud services.